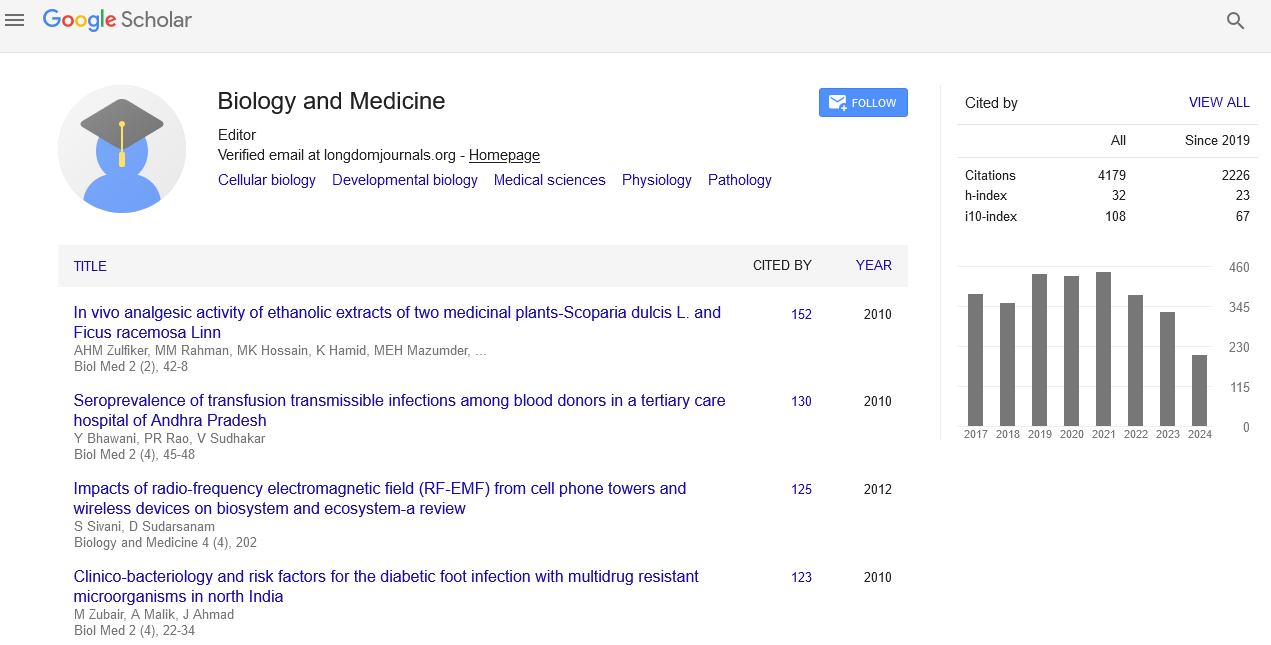

Indexed In
- Open J Gate
- Genamics JournalSeek
- CiteFactor
- Cosmos IF
- Scimago
- Ulrich's Periodicals Directory
- Electronic Journals Library
- RefSeek
- Hamdard University
- EBSCO A-Z
- Directory of Abstract Indexing for Journals
- OCLC- WorldCat
- Proquest Summons
- Scholarsteer
- ROAD
- Virtual Library of Biology (vifabio)
- Publons
- Geneva Foundation for Medical Education and Research
- Google Scholar
Useful Links
Share This Page
Journal Flyer

Open Access Journals
- Agri and Aquaculture
- Biochemistry
- Bioinformatics & Systems Biology
- Business & Management
- Chemistry
- Clinical Sciences
- Engineering
- Food & Nutrition
- General Science
- Genetics & Molecular Biology
- Immunology & Microbiology
- Medical Sciences
- Neuroscience & Psychology
- Nursing & Health Care
- Pharmaceutical Sciences
Research Article - (2023) Volume 15, Issue 10
Beta-Validation of a Non-Invasive Method for Simultaneous Detection of Early-Stage Female-Specific Cancers
Sudhakar Ramamoorthy1, Saranya Sundaramoorthy2, Ankur Gupta3,4, Zaved Siddiqui3,4, Ganga Sagar3, Kanury V.S. Rao3, Najmuddin Saquib3,4* and Surapaneni Krishna Mohan2*2Department of Biochemistry, Clinical Skills & Simulations Research, Panimalar Medical College Hospital & Research Institute, Chennai, India
3PredOmix Technologies Private Limited Tower B, Gurugram, Haryana, India
4PredOmix Health Sciences Private Limited, Singapore
Received: 09-Oct-2023, Manuscript No. BLM-23-23461; Editor assigned: 12-Oct-2023, Pre QC No. BLM-23-23461 (PQ); Reviewed: 26-Oct-2023, QC No. BLM-23-23461; Revised: 03-Nov-2023, Manuscript No. BLM-23-23461 (R); Published: 10-Nov-2023, DOI: 10.35248/0974-8369.23.15.614
Abstract
Aim and Objectives: In this report, we assessed the accuracy of our previously developed method for simultaneous diagnosis of the four female cancers of the Breast, Endometrium, Cervix, and Ovary, in a clinical set-up with blinded protocol.
Materials and Methods: Our test protocol combined global serum metabolome profiling wherein data was analyzed with machine learning algorithms to extract metabolite signatures that correlated with early-stage cancers. High-resolution mass spectrometry was employed to profile the serum metabolome and the resulting data were subjected to a pre-processing pipeline to obtain the data set. The data was then analyzed using artificial intelligence algorithms to identify early-stage cancer metabolic signatures.
Results: Overall, a total of 1000 blinded samples were analyzed by generating the serum metabolome profiles, followed by sequential algorithms for cancer detection and multiclass cancer type identification. Of these 1000 samples, 797 were identified as cancer positive, while, 203 samples were identified as cancer-negative. The multiclass algorithm was then applied to the 797 cancer-positive samples, to distinguish between samples that were from patients with either endometrial, breast, cervical, or ovarian cancer. After completion of the analysis, the sample code was broken to estimate the accuracy of the results. Concerning the identification of samples that were cancer-positive, the sensitivity obtained was 99.6% whereas the specificity was 100%. For the second stage of analysis which involves ‘tissue of origin’, all 107 breast cancer samples were correctly identified without any false calls. The accuracy for identification of cervical and ovarian cancers was between 95%- 96% for each, whereas 91% for endometrial cancer.
Conclusions: Our present study validates the performance of our method for the early-stage detection of female-specific cancers in a clinical setting. Importantly, the algorithms for cancer detection and ‘tissue of origin’ prediction, which were initially trained using samples from Caucasian patients, retained the accuracy on samples from Indian women patients. This suggests that the performance of these algorithms was minimally influenced by variables such as ethnicity and race. Present results, therefore, also underscore the potential clinical utility of our method for early-stage diagnosis of cancers that are specific to females.
Keywords
Breast cancer, Endometrial cancer, Cervical cancer, Ovarian cancer, Untargeted metabolomics, Machine learning; Tissue of Origin (TOO)
Abbreviations
TOO: Tissue of Origin; hrHPV: high-risk Human Papilloma Virus
Introduction
Worldwide over 6 million new cancer cases and close to 4 million cancer related deaths are reported every year [1,2]. The most prominent female-specific cancers are those of the breast, cervix, endometrium, and ovary [1,3]. Breast cancer is the most common and represents ¼th of cancers in women [4], whereas cancer of the endometrium and ovary account for 5% and 4% respectively [5,6]. Cervical cancer ranks fourth with an estimated 500,000 cases globally [7].
These cancers are often detected at their more advanced stages of progression. Consequently, prognosis is usually poor [2,8,9]. While treatment outcomes are significantly improved when the cancer is detected at an early stage [10], effective screening paradigms for early-stage female-specific cancers are either not currently available or suffer from inherent limitations that restrict their scope [11,12]. For example, while mammography is the recommended method for breast cancer screening, it is not a perfect test because its overall sensitivity ranges only from 75% to 85% [13]. The sensitivity further decreases sharply in the case of dense breast parenchyma [14]. The net consequence of these limitations is that many women with breast cancer are missed [14]. Another downside to mammography is its relatively high false- positivity rate, which is further enhanced in women below the age of 40 years. As a result, the likelihood that a woman will receive at least 1 false-positive call after 10 yearly mammograms is found to be as high as 61% [15]. It follows, therefore, that an improved breast cancer screening method with high sensitivity and specificity across all age groups of women is clearly needed to minimize the harm to benefit ratio and, thereby, obtain better outcomes. Efforts to achieve this are presently ongoing [16].
Current guidelines recommend three primary screening options for cervical cancer. These are cytological testing alone, standalone high- risk Human Papilloma Virus (hrHPV) testing, and co-testing with the combination of cytological and hrHPV testing [17]. While cytological testing is more widely accepted as the primary screening method for cervical cancer [18], it suffers from poor sensitivity (47%-70%) although the specificity is high [19]. In contrast, hrHPV standalone testing yields higher sensitivity (80%), but with a higher false positivity rate of about 15% [20,21]. While sensitivity can be improved upon co-testing with both methods this, however, was shown to occur at the cost of lower specificities [20]. In contrast to at least some screening methods being available for breast and cervical cancer, no such routine or standard screening test is currently available for either endometrial or ovarian cancer. Indeed, most ovarian cancer patients do not experience symptoms until its later stages. The only recourse currently available is to either measure levels of the relatively non-specific tumor marker CA 125 in the blood, or to perform a pelvic ultrasound. However, because of poor sensitivity especially for early-stage cancer, and a high false-positivity rate, neither of these tests currently qualify as standalone screening tests for ovarian cancer [22,23]. These collective results clearly highlight the need for developing more accurate and reliable methods for screening of each of these cancers. The ideal solution here would be a non-invasive test that would enable more effective surveillance of at least the more vulnerable segments of the female population.
In an earlier report we had described the development of a method for the concomitant early-stage detection of these female-specific cancers with very high accuracy. Our protocol combined untargeted metabolomics with machine learning based data analysis to extract metabolite patterns that define the early-stage cancers [24]. The accuracy of detection obtained across all four cancers was 98% while a subsequent analysis also helped to identify the cancer type of the individual cancer-positive samples with reasonable accuracy. For the development of this test, we had employed stored serum samples that were obtained from biobanks. To evaluate its potential for clinical use, however, it was important for us to ascertain its performance with samples that were directly obtained from women patients in a clinical setting. The present report describes our efforts in this direction. Results obtained establish that the fidelity of both cancer detection and prediction of the Tissue of Origin (TOO) remained exceptionally high upon analysis of serum samples collected directly from women volunteers. Importantly, we were also able to obtain beta-validation of our method by confirming its accuracy in a blinded study protocol.
Materials and Methods
Study design and sample collection
Blood, from both cancer patients and normal female volunteers, were collected at the Panimalar Medical College Hospital and Research Institute after first obtaining approval from the Panimalar Medical College Hospital & Research institute, Institutional Human Ethics Committee (Protocol No. PMCHRI-IHEC-034). Serum was subsequently prepared, and the samples were anonymized before submitting to the analytical team (AG, GS, ZS, KVSR, NS) for analysis.
Sample accessioning
Unique identity number (identifier) issued to each sample post arrival to lab. These identifiers were used for queries related to sample handling, tasks, and results. Samples were stored frozen (-80°C) until required.
Metabolite extraction
Extraction of metabolite was done as earlier reported by Gupta et al., [24]. Briefly, serum samples were thawed at 4°C on ice. 10 μl of each sample was taken and metabolites were extracted and processed for UHPLC-MS/MS as previously described [24].
Liquid chromatography coupled with high resolution mass spectroscopy
The detailed method of untargeted metabolomics was previously reported by Gupta et.al [24]. Briefly, a Dionex LC system was employed for the high-resolution separation of serum metabolite in normal and cancer patients.
10 μl of each sample was resolved by UHPLC prior to MS/MS analysis as previously described [24].
Data processing
Data generated by mass spectrometers was pre-processed through the steps of mass error correction, ion filtering, and normalisation as described earlier by Gupta et.al [24].
AI modeling of the data:
Detailed explanation of the method was shown by Gupta et al., [24]. Briefly, a layered approach was used, where we first distinguish cancer from normal and then between each of the cancers. The scheme employed for training, testing and validation along with method used for determining sensitivity and specificity was as previously described [24].
Results
Study rationale and the samples employed
In our previous study we had developed a method, by integrating untargeted serum metabolomics by mass spectrometry and analysis of the resulting data with a machine learning algorithm to diagnose Stage 0/I of female cancers with high fidelity [24]. These were breast, endometrial, cervical and ovarian cancers. Our protocol involved a sequential approach in which the cancer-positive samples were first distinguished from the non-cancer samples. Subsequent to this, multi-class algorithm was employed to differentiate between each of the separate cancers of the cancer-positive subset. The high accuracy obtained in this study suggested the possibility that this approach could indeed be further developed as a screening tool for the early- stage female-specific cancers.
Although our results were extremely promising, we recognized that our analysis algorithms had been developed using serum samples obtained from commercial biobanks [24]. Therefore, to further explore its utility, it was necessary to evaluate the performance of our test under more relevant conditions where samples were directly obtained from patients in a clinical setting [25-27]. Another important point here was that, for the algorithm development, we had employed metabolome profiles of sera that had been primarily derived from Caucasian patients. Therefore, since the metabolome composition is known to vary across different populations [28,29], it was also relevant to establish whether these algorithms were equally effective when samples obtained from Indian women patients were tested. This question was especially pertinent given that our objective was to identify metabolite signatures that specifically characterized the disease state of interest, independent of other variables such as age, ethnicity, race, etc. We, therefore, undertook the present exercise to ascertain the accuracy of our method [24] when tested on samples directly obtained from Indian women patients.
Verification of algorithm performance for identification of Indian women patients
Our first objective was to test the performance accuracy of our earlier developed algorithms, which were developed using data largely generated from Caucasian samples, in Indian patients. For this we used a set of 300 samples collected at the Panimalar Medical College Hospital and Research Institute (PMCHRI). Of these, 71 samples each were from patients with endometrial, cervical, or ovarian cancer, where the remaining 87 samples were from breast cancer patients. In addition, we also included 200 samples from normal volunteers. The distribution across age groups, BMI status, and cancer stages are given in Table 1.
| Sample Clinical Info | ||||||
|---|---|---|---|---|---|---|
| Clinical Status | ||||||
| Parameter | Intervals | Normal control (n=200) | Endometrial cancer (n=71) | Breast cancer (n=87) | Cervical cancer (n=71) | Ovarian cancer (n=71) |
| Age (years) | 20-30 | 102 | 0 | 8 | 1 | 5 |
| 31-40 | 51 | 2 | 26 | 5 | 17 | |
| 41-50 | 29 | 17 | 19 | 7 | 27 | |
| 51-60 | 14 | 35 | 28 | 24 | 16 | |
| 61-70 | 4 | 13 | 3 | 20 | 5 | |
| 71-80 | 0 | 4 | 3 | 13 | 0 | |
| 81-90 | 0 | 0 | 0 | 1 | 1 | |
| BMI (Kg/m2) | 10 to 30 | 154 | 57 | 68 | 57 | 56 |
| >30 | 24 | 14 | 19 | 12 | 15 | |
| Cancer stage | 1 | 26 | 32 | 29 | 21 | |
| 2 | 38 | 46 | 34 | 32 | ||
| 3 | 4 | 3 | 3 | 11 | ||
| 4 | 3 | 6 | 5 | 7 | ||
Table 1: Demographic, BMI, and Cancer-stage grouping of the samples employed for algorithm verification.
Metabolites were extracted from each of the samples and then analyzed as previously described [24]. Range of the unique metabolite numbers detected in normal control samples and the individual cancers, across the individual age groups, are depicted in Figure 1. The data was subsequently processed our previously described in-house pipeline to eventually extract the matrix consisting of 2764 features [24].

Figure 1: Age-wise detection of detected metabolites. Figure provides a graphical representation of the number of metabolites detected across the individual age groups, for the normal control set as well as the individual cancer groups. The cumulative unique metabolites detected in normal control samples were 5371. While, endometrial, breast, cervical and ovarian cancer samples were found to have 4947, 5132, 5035 and 5041 respectively.
The PLSDA plot generated using the matrix is shown in Figure 2. It is evident from this figure that the cancer samples could be unambiguously separated from the normal controls. To differentiate the cancer samples from normal controls, we applied our previously developed AI model [24] on the present data as the test set. As described in our earlier report [24], the model applies a logistic regression function to separate the female-specific cancer samples from the control group. After training the algorithm calculates a score for the individual samples by using the following formula:
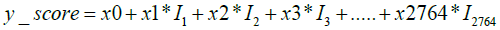
Here, x0 is a constant number, Ii (1<=i<=2764) is the intensity of metabolite present in the respective sample.

Figure 2: PLSDA plot distinguishes between the cancer group and also the normal controls. Figure presents a PLSDA plot of the matrix of sample-
specific metabolites versus metabolite intensity for normal controls and the group of women-specific cancer samples. The separation obtained between
them is shown. The R2 value obtained is included. 
The schematic of the approach employed is illustrated in Figure 3 and Figure 4A shows the results obtained after applying the model on the test set [24]. The scatter diagram gives the scores generated by the model for control and the cancer cases. It is evident from the figure that the scores for the normal control samples are clearly distinguished from those for the cancer set. A cut-off score of 5 successfully differentiated the two sets as depicted in Figure 4B. Sensitivity, Specificity, and Accuracy all corresponded to 100%.

Figure 3: Schematic of the approach employed for identifying women-specific cancer positive samples in the Indian test dataset. Illustrated here is
the procedure adopted for identifying the cancer-positive samples in the Indian Test dataset. The grey box represents the previously trained model
for cancer detection and tissue type identification [24]. The Test dataset was first processed using the data processing steps followed previously in the
study [24]. The final processed data was tested first for the identification of cancer samples in the dataset, the cancer positive identified cases were
next further tested using the one versus rest models trained previously for cancer tissue type prediction [24]. 
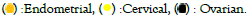

Figure 4: Distinguishing women-specific cancers from normal controls. Results obtained for testing of our previous trained model for distinguishing the women-specific cancer group from normal on the data set generated from Indian patient and normal controls is shown here [24]. The separation achieved between the cancer and normal control groups is shown in Panel A and the resulting confusion matrix that was generated is shown in Panel B. Values obtained for Sensitivity, Specificity, and Accuracy are also given.
Differentiating between breast, endometrial, cervical and ovarian cancer samples
Next, to distinguish the specific cancer types among the positive samples identified in Figure 4, we layered the multiclass AI model over the model described in this figure. The multiclass AI model was also developed in our earlier study [24]. It is a One Versus Rest (OVR) classifier model, which gives four scores for each sample. Each of these scores define the likelihood of a given sample belonging to anyone of the four classes. As previously described [24], the formulae used by the algorithm to calculate the four scores for each of the sample is as follows:
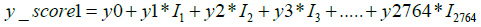
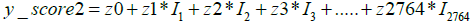
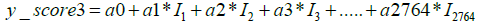
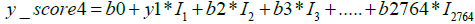
y0, z0, a0, b0 represent constant numbers, Ii (1<=i<=2764) is the relative concentration of metabolite i in the respective sample.
To assess the performance of our multiclass model in terms of differentiating between the individual cancer types for Indian patients, as also from normal controls, the scores obtained from the model were plotted. In Figure 5A, we plotted the score obtained for Endometrial cancer samples against that of the group comprising of the Breast, Cervical and Ovarian (BCO) cancers. A clear distinction between Endometrial and BCO Cancer samples is seen (Figure 5A). Control samples were also included in this analysis and sensitivity, specificity and accuracy obtained were 97%, 94%, and 95% respectively.

Figure 5: Testing the multiclass model for its ability to distinguish the individual cancer groups. Panel (A) shows the results of specifically testing the multiclass breast, cervical, ovarian; abbreviated as BCO) based on model’s Endometrial scores. The resulting confusion matrix on applying a threshold shows good accuracy, sensitivity, and specificity. Panel (B) shows results of specifically testing the multiclass trained model for separation of breast cancer samples from the other cancers based on model’s Breast scores. The resulting confusion matrix on applying a threshold shows good accuracy, sensitivity, and specificity. Panel (C) the results of specifically testing the multiclass trained model for separation of cervical cancer samples from the other cancers based on model’s Cervical scores. The resulting confusion matrix on applying a threshold shows good accuracy, sensitivity, and specificity. Panel (D) shows results of specifically testing the multiclass trained model for separation of ovarian cancer samples from the other cancers.
Next, we plotted the Breast cancer sample scores versus those of the group comprised of Endometrial, Cervical and Ovarian (ECO) cancer samples (Figure 5B). Here again Breast Cancer could be clearly distinguished from ECO cancer sample set as shown (Figure 5B). The sensitivity, specificity and accuracy obtained were 94%, 93.8%, and 93.9% respectively.
Figure 5C depicts the confusion matrix obtained for an analysis of cervical cancer sample scores versus that for the group of Endometrial, Breast and Ovarian (EBO) cancer samples. Sensitivity, specificity and accuracy obtained were 92%, 97%, and 96% respectively. And, finally, Figure 5D shows the confusion matrix obtained for discriminating ovarian cancer samples from the group comprising of Endometrial, Breast and Cervical (EBC) Cancer samples. Here, the calculated the sensitivity, specificity and accuracy were 98.5%, 97.7%, and 97.6% respectively.
Beta-validation of our algorithms through a blinded study protocol
The results obtained so far establish that the algorithms that we had previously developed, using data primarily generated with samples obtained from Caucasians [24], were equally effective for screening of female-specific cancers in Indian women. Indeed, the high sensitivity and specificity obtained, for both detection of cancer positivity as well as for identification of cancer type, also suggest that this approach is likely to be at least less sensitive to population-related differences in the subjects. To further verify the potential clinical utility of our test platform, we sought to beta-validate it by employing a blinded protocol. In this, coded samples we sent by the clinical team (SR, SS, SKM) to the team involved in sample analysis and diagnosis of the cancer state and type (analytics team, AG, GS, ZS, NS, KVSR). Here, all Public Health Information (PHI) identifiers/variable were protected from the latter team. Apart from sample IDs, no information on either cancer status or cancer type were provided.
A total of 1000 samples were provided by the clinical team, which the analytical team then analysed by generating the corresponding serum metabolome profiles, followed by sequential application of the cancer detection and multiclass cancer type identification algorithms. Of these 1000 samples, 797 were identified as cancer positive, whereas the remaining 203 samples were identified as cancer negative. Following this, the multiclass algorithm was then applied to the 797 samples putatively identified as cancer positive, in order to distinguish those samples that were patients with either endometrial, breast, cervical, or ovarian cancer. The cumulative results were then sent to the clinical team, which then broke the code and summarized their findings. These findings are presented in Tables 2 and 3 where Table 2 provides the results generated with the first algorithm for identification of cancer positive samples. It is evident from this table that very high detection accuracy was obtained, with no false positives and only 3/800 true positive samples being missed as false negatives [25-30]. The sensitivity obtained here was 99.6%, with a specificity of 100% (Table 2). Table 3 presents the results obtained after application of the multiclass algorithm for distinguishing between samples from patients with either breast, endometrial, cervical, or ovarian cancer. Here, the algorithm was only applied to the 797 blinded samples that were identified as cancer positive in Table 2. The results in Table 3 clearly underscore the high degree of fidelity with which the individual cancer types could be distinguished. While all 107 of the breast cancer samples were correctly identified, the accuracy for identification of cervical and ovarian cancer samples was between 95%-96%. Endometrial cancer identification was, however, somewhat lower with an accuracy of close to 91% (Table 3). These results, therefore, provide strong validation for our method, which integrates untargeted metabolome profiling with AI-driven data analytics, for concurrent detection of female-specific cancers [25-30].
| Total #samples provided | 1000 |
| True positives identified | 797 |
| True negatives identified | 200 |
| False positives identified | 0 |
| False negatives identified | 3 |
| Sensitivity | 99.6% (797/800) |
| Specificity | 100% (200/200) |
Table 2: Identification of women-specific cancer patients from the blinded sample set.
| Cancer type | #Samples correctly identified | Accuracy (%) |
|---|---|---|
| Breast cancer | 107/107 | 100 |
| Endometrial cancer | 272/299 | 90.97 |
| Cervical cancer | 184/192 | 95.8 |
| Ovarian cancer | 190/199 | 95.5 |
Table 3: Identification of the cancer type (TOO).
Discussion and Conclusion
While there is an increased emphasis on detection of cancers at an early stage, recent years are also witnessing a paradigm shift towards multiple cancer detection with a single blood draw. These latter efforts have largely focused on analysis of circulating tumour cell-free DNA (ctDNA) by using genomic technologies and machine learning to not only detect multiple cancers simultaneously but also identify the Tissue of signal Origin (TOO) [31-35]. The promise that such Multi-Cancer Detection (MCD) tests hold is that they would permit detection of several cancers that otherwise go undetected until they reach an advanced stage [36]. Indeed, mathematical modelling of the potential public health impact of including multi-cancer detection tests to usual care suggested a marked positive effect with a substantial reduction in overall cancer mortality [37-39].
Despite the promise shown by MCDs based on ctDNA analysis, concerns have been raised that ctDNA may be a less than satisfactory proxy for liquid biopsies of tumour tissues for early detection because of limitations in both sensitivity and specificity. In this context, the low concentration of ctDNA and its variability based on type and status of the tumour also contributes as a complicating factor [40]. Furthermore, the low to negligible concentration of ctDNA present in the early stages of cancer also limits the sensitivity that can be achieved for the stages [41,42]. This concern is borne out by more recent results from clinical trials where sensitivity of detection of early-stage cancers was indeed found to be low [34,35]. Given these potential limitations with ctDNA, we preferred to test the utility of metabolomics for early-stage cancer detection. The rationale here was based on the now widely accepted notion that metabolites serve as proximal reporters of disease since their relative abundances are often directly related to pathogenic mechanisms [43-45]. We hypothesized that metabolomics should be an especially relevant technique for cancer detection since cancers have significantly altered metabolism [46,47]. Therefore, the spectrum of metabolites produced can possibly yield signatures characteristic of the presence of cancer.
As demonstrated in our previous report and the results described here, our expectation was indeed borne out. At least in the context of the four female-specific cancers, serum metabolome analysis coupled with AI analysis yielded a very accurate method for their simultaneous detection at the early stage, and subsequent of the Tissue of Origin (TOO) . Indeed the high sensitivity obtained for detection of Stage-I of all the four cancers is particularly notable and unmatched by that achieved through analysis of ctDNA [34,35]. We do, however, acknowledge that our current method only enables simultaneous detection of the four female-specific cancers. Nonetheless, an important highlight of our present study is that it validates the performance of our method in a clinical setting. Particularly notable here is the fact that the algorithms for cancer detection and TOO prediction, which were trained primarily on samples from Caucasian patients, retained their accuracy with samples from Indian women patients [24]. This indicated that, at least with respect to the two population groups studied, variables such as ethnicity and race did not affect performance of either algorithm. Indeed, the high sensitivity and specificity of >99% obtained for detection of the cancer positive samples, and the high TOO prediction accuracy, in the blinded study especially underscore this, while also serving to validate the method developed by us. We do recognize, however, that a more extensive clinical trial would be required to demonstrate its clinical utility. Furthermore, it will also be of interest to explore whether early detection of additional cancers can be brought within the ambit of this approach.
Data Availability
All data produced in the present study are available upon reasonable request to the authors.
Author Contributions
S.R, S.S., and S.K.M. coordinated the procurement of patient samples and confirmation of their diagnosis. N.S., G.S., and Z.S. led all experimental aspects of the study while data analysis was performed by A.G. The study was jointly supervised by K.V.S.R. and S.K.M. N.S., K.V.S.R., and S.K.M. wrote the paper.
Competing Financial Interests
A.G, G.S., Z.S. and N.S. are fulltime employees of PredOmix Technologies Private Limited. K.V.S.R. is a cofounder and owns stock in both PredOmix Technologies Private Limited and PredOmix Health Sciences Pte. Ltd. A.G., Z.S., and NS. own stock in PredOmix Health Sciences Pte. Ltd.
References
- Torre LA, Islami F, Siegel RL, Ward EM, Jemal A. Global cancer in women: Burden and trends. Cancer Epidemiol Biomarkers Prev. 2017;26(4):444-457.
- Siegel RL, Miller KD, Fuchs HE, Jemal A. Cancer statistics, 2021. CA Cancer J Clin. 2021;71(1):7-33.
- Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A, et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2021;71(3):209-249.
- Ghoncheh M, Pournamdar Z, Salehiniya H. Incidence and mortality and epidemiology of breast cancer in the world. Asian Pac J Cancer Prev. 2016;17:43-46.
- Zhang S, Gong TT, Liu FH, Jiang YT, Sun H, Ma XX, et al. Global, regional, and national burden of endometrial cancer, 1990-2017: Results from the global burden of disease study, 2017. Front Oncol. 2019;9:1440.
- Momenimovahed Z, Tiznobaik A, Taheri S, Salehiniya H. Ovarian cancer in the world: epidemiology and risk factors. Int J Womens Health. 2019;30:287-299.
- Arbyn M, Weiderpass E, Bruni L, de Sanjosé S, Saraiya M, Ferlay J, et al. Estimates of incidence and mortality of cervical cancer in 2018: A worldwide analysis. Lancet Glob Health. 2020;8(2):191-203.
- Howlader N. SEER Cancer Statistics Review, 1975-2014. National Cancer Institute. 2017.
- Ahlquist DA. Universal cancer screening: revolutionary, rational, and realizable. NPJ Precis Oncol. 2018;2(1):23.
- World Health Organization. Guide to early cancer diagnosis. 2017.
- Pinsky PF, Prorok PC, Kramer BS. Prostate Cancer Screening-A Perspective on the Current State of the Evidence. N Engl J Med. 2017;376(13):1285-1289.
- Subramanian S, Klosterman M, Amonkar MM, Hunt TL. Adherence with colorectal cancer screening guidelines: A review. Prev Med. 2004;38(5):536-550.
- Gøtzsche PC, Jørgensen KJ. Screening for breast cancer with mammography. Cochrane Database Syst Rev. 2013.
- Chen HL, Zhou JQ, Chen Q, Deng YC. Comparison of the sensitivity of mammography, ultrasound, magnetic resonance imaging and combinations of these imaging modalities for the detection of small (≤ 2 cm) breast cancer. Medicine (Baltimore). 2021;100(26).
- Hubbard RA, Kerlikowske K, Flowers CI, Yankaskas BC, Zhu W, Miglioretti DL. Cumulative probability of false-positive recall or biopsy recommendation after 10 years of screening mammography: a cohort study. Ann Intern Med. 2011;155(8):481-92.
- Gastounioti A, Desai S, Ahluwalia VS, Conant EF, Kontos D. Artificial intelligence in mammographic phenotyping of breast cancer risk: A narrative review. Breast Cancer Res. 2022;24(1):1-2.
- Terasawa T, Hosono S, Sasaki S, Hoshi K, Hamashima Y, Katayama T, et al. Comparative accuracy of cervical cancer screening strategies in healthy asymptomatic women: A systematic review and network meta-analysis. Sci Rep. 2022;12(1):94.
- Nkwabong E, Laure Bessi Badjan I, Sando Z. Pap smear accuracy for the diagnosis of cervical precancerous lesions. Trop Doct. 2019;49(1):34-39.
- Boone JD, Erickson BK, Huh WK. New insights into cervical cancer screening. J Gynecol Oncol. 2012;23(4):282-287.
- Liang LA, Einzmann T, Franzen A, Schwarzer K, Schauberger G, Schriefer D, et al. Cervical cancer screening: comparison of conventional Pap smear test, liquid-based cytology, and human papillomavirus testing as stand-alone or cotesting strategies. Cancer Epidemiol Biomarkers Prev. 2021;30(3):474-484.
- Longatto-Filho A, Naud P, Derchain SF, Roteli-Martins C, Tatti S, Hammes LS, et al. Performance characteristics of Pap test, VIA, VILI, HR-HPV testing, cervicography, and colposcopy in diagnosis of significant cervical pathology. Virchows Arch. 2012;460:577-585.
- Menon U, Gentry-Maharaj A, Burnell M, Singh N, Ryan A, Karpinskyj C, et al. Ovarian cancer population screening and mortality after long-term follow-up in the UK Collaborative Trial of Ovarian Cancer Screening (UKCTOCS): A randomised controlled trial. Lancet. 2021;397(10290):2182-2193.
- Henderson JT, Webber EM, Sawaya GF. Screening for ovarian cancer: Updated evidence report and systematic review for the US preventive services task force. JAMA. 2018;319(6):595-606.
- Gupta A, Sagar G, Siddiqui Z, Rao KV, Nayak S, Saquib N, et al. A non-invasive method for concurrent detection of early-stage women-specific cancers. Sci Rep. 2022;12(1):2301.
- Brochu F, Plante PL, Drouin A, Gagnon D, Richard D, Durocher F, et al. Mass spectra alignment using virtual lock-masses. Sci Rep. 2019;9(1):8469.
- Kohl SM, Klein MS, Hochrein J, Oefner PJ, Spang R, Gronwald W. State-of-the art data normalization methods improve NMR-based metabolomic analysis. Metabolomics. 2012;8:146-160.
- Gromski PS, Xu Y, Kotze HL, Correa E, Ellis DI, Armitage EG, et al. Influence of missing values substitutes on multivariate analysis of metabolomics data. Metabolites. 2014;4(2):433-452.
- Lau CH, Siskos AP, Maitre L, Robinson O, Athersuch TJ, Want EJ, et al. Determinants of the urinary and serum metabolome in children from six European populations. BMC Med. 2018;16:1-9.
- Tkachev A, Stepanova V, Zhang L, Khrameeva E, Zubkov D, Giavalisco P, et al. Differences in lipidome and metabolome organization of prefrontal cortex among human populations. Sci Rep. 2019;9(1):18348.
- Liu MC. Transforming the landscape of early cancer detection using blood tests-Commentary on current methodologies and future prospects. Br J Cancer. 2021;124(9):1475-1477.
- Cohen JD, Li L, Wang Y, Thoburn C, Afsari B, Danilova L, et al. Detection and localization of surgically resectable cancers with a multi-analyte blood test. Science. 2018;359(6378):926-930.
- Liu MC, Oxnard GR, Klein EA, Swanton CS, Seiden MV, Liu MC, et al. Sensitive and specific multi-cancer detection and localization using methylation signatures in cell-free DNA. Ann Oncol. 2020;31(6):745-759.
- Chen X, Gole J, Gore A, He Q, Lu M, Min J, et al. Non-invasive early detection of cancer four years before conventional diagnosis using a blood test. Nat Commun. 2020;11(1):3475.
- Klein EA, Richards D, Cohn A, Tummala M, Lapham R, Cosgrove D, et al. Clinical validation of a targeted methylation-based multi-cancer early detection test using an independent validation set. Ann Oncol. 2021;32(9):1167-1177.
- Lennon AM, Buchanan AH, Kinde I, Warren A, Honushefsky A, Cohain AT, et al. Feasibility of blood testing combined with PET-CT to screen for cancer and guide intervention. Science. 2020;369(6499):9601.
- Ahlquist DA. Universal cancer screening: revolutionary, rational, and realizable. NPJ Precis Oncol. 2018;2(1):23.
- Hubbell E, Clarke CA, Aravanis AM, Berg CD. Modeled reductions in late-stage cancer with a multi-cancer early detection test. Cancer Epidemiol Biomarkers Prev. 2021;30(3):460-468.
- Fiala C, Diamandis EP. Circulating tumor DNA (ctDNA) is not a good proxy for liquid biopsies of tumor tissues for early detection. Clin Chem Lab Med. 2020;58(10):1651-1653.
- Keller L, Belloum Y, Wikman H, Pantel K. Clinical relevance of blood-based ctDNA analysis: mutation detection and beyond. Br J Cancer. 2021;124(2):345-358.
- Yasai H. Challenges in circulating tumor DNA analysis for cancer diagnosis. J Nanomed Res. 2018;972:76-80.
- Fiala C, Diamandis EP. Utility of circulating tumor DNA in cancer diagnostics with emphasis on early detection. BMC Med. 2018;16(1):1.
- Molparia B, Nichani E, Torkamani A. Assessment of circulating copy number variant detection for cancer screening. PLoS One. 2017;12(7):0180647.
- Shao Y, Le W. Recent advances and perspectives of metabolomics-based investigations in Parkinson’s disease. Mol Neurodegener. 2019;14:1-2.
- Beger RD, Dunn W, Schmidt MA, Gross SS, Kirwan JA, Cascante M, et al. Metabolomics enables precision medicine:“A white paper, community perspective”. Metabolomics. 2016;12:1-5.
- Puchades-Carrasco L, Pineda-Lucena A. Metabolomics applications in precision medicine: an oncological perspective. Curr Top Med Chem. 2017;17(24):2740-2751.
- Beger RD. A review of applications of metabolomics in cancer. Metabolites. 2013;3(3):552-574.
- Wang L, Liu X, Yang Q. Application of metabolomics in cancer research: As a powerful tool to screen biomarker for diagnosis, monitoring and prognosis of cancer. Biomark J. 2018;4(3):12.
Citation: Ramamoorthy S, Sundaramoorthy S, Gupta A, Siddiqui Z, Sagar G, Rao KVS, et al. (2023) Beta-Validation of a Non-Invasive Method for Simultaneous Detection of Early-Stage Female-Specific Cancers. Bio Med. 15:614.
Copyright: © 2023 Ramamoorthy S, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.