Awards Nomination
20+ Million Readerbase


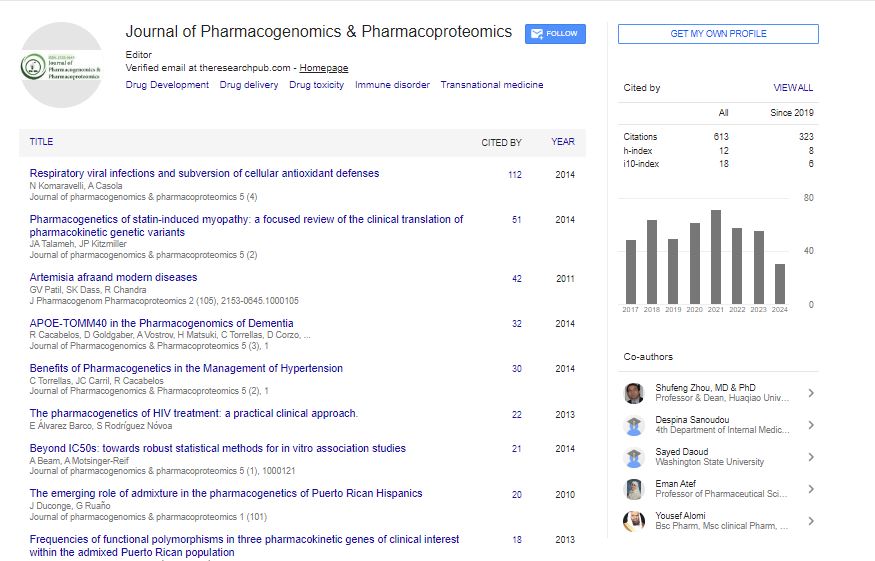
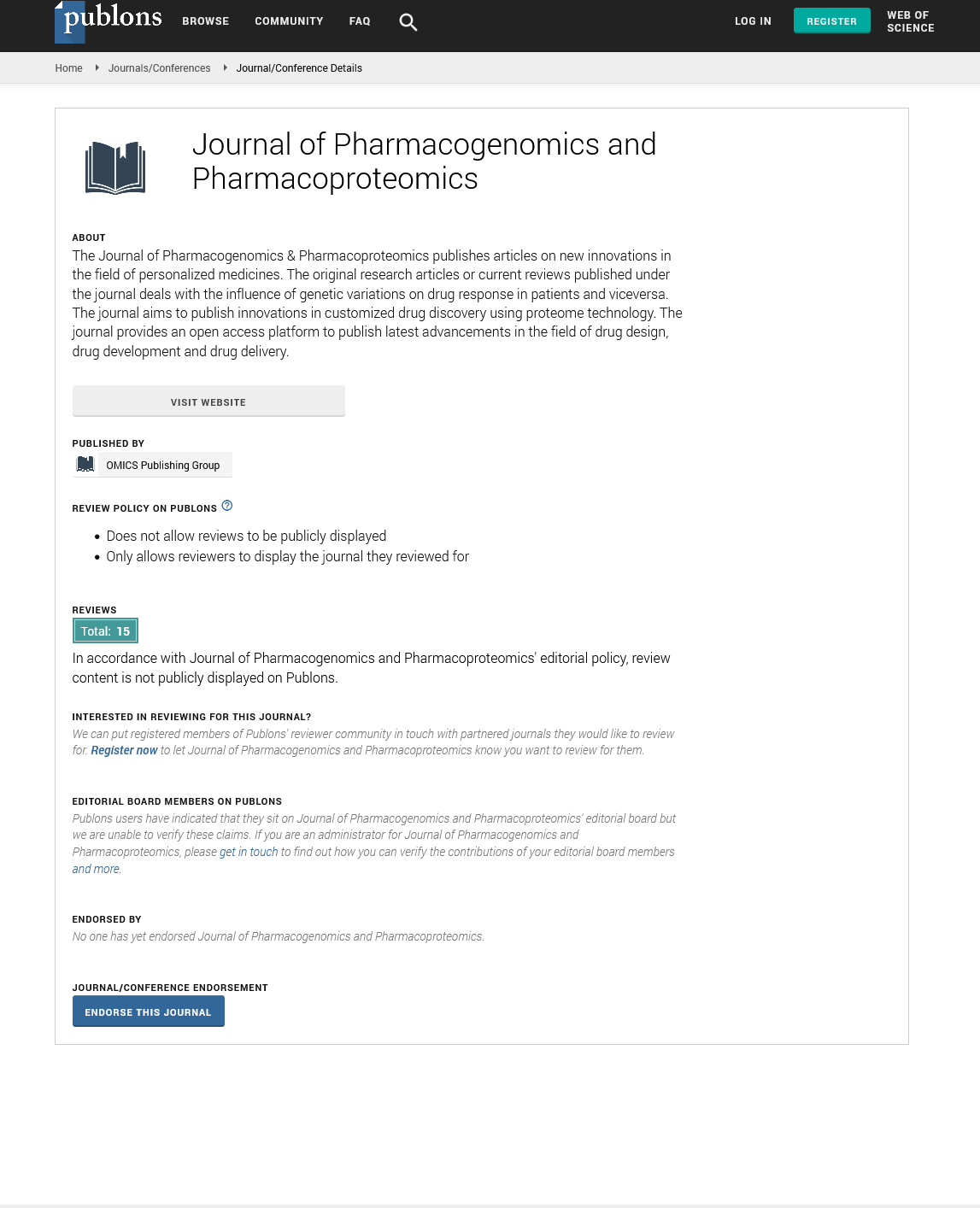

Indexed In
- Open J Gate
- Genamics JournalSeek
- Academic Keys
- JournalTOCs
- ResearchBible
- Electronic Journals Library
- RefSeek
- Hamdard University
- EBSCO A-Z
- OCLC- WorldCat
- Proquest Summons
- SWB online catalog
- Virtual Library of Biology (vifabio)
- Publons
- MIAR
- Euro Pub
- Google Scholar
Useful Links
Share This Page
Journal Flyer
Open Access Journals
- Agri and Aquaculture
- Biochemistry
- Bioinformatics & Systems Biology
- Business & Management
- Chemistry
- Clinical Sciences
- Engineering
- Food & Nutrition
- General Science
- Genetics & Molecular Biology
- Immunology & Microbiology
- Medical Sciences
- Neuroscience & Psychology
- Nursing & Health Care
- Pharmaceutical Sciences